On cause Python Type Hints et architecture hexagonale dans Django
Ces derniers mois, j'ai plongé dans deux concepts que j'avais soigneusement évités jusque-là en Python : les type hints et l'architecture hexagonale. Bien que sceptique au départ, ces outils ont fini par se glisser dans mon quotidien de développeur. Dans cet article, je partage mon retour d'expérience, mes réticences initiales, et comment ces pratiques ont changé ma façon de concevoir des applications en Django.
Je n'écris plus ici depuis quelque temps, c'est dommage. C'est-à-dire que depuis mon dernier article, la vie a un peu changé. Je suis pas mal occupé.
J'ai démarré un boulot pour un gros éditeur de logiciel français. Je suis encore en train de m'y acclimater et ça me prend beaucoup de temps.
À côté de ça, j'ai été recruté par le plus ancien groupe de punk rock nantais encore en activité, les Toxxic TV, pour chanter avec eux. Ça a donné lieu à beaucoup de répétitions et tout un répertoire à apprendre. En parallèle de NDA, sinon ce n'est pas drôle.
Pour NDA justement, je continue d'assurer le booking, et on travaille à composer notre premier album. Les échéances vont vite arriver.
Enfin, je suis toujours en train de développer https://www.francepunkscene.net, dont je suis très content. C'est de loin mon projet de développement le plus abouti. J'ai des utilisateurs, l'agenda le plus complet dans sa catégorie, et toujours plus de features.
Ces temps-ci, je suis en train de me laisser convaincre par deux concepts que j'avais évités jusque-là en python. Je suis en train de creuser le sujet sur francepunkscene.net, et c'est de ça dont j'avais envie de parler. C'est un peu long, je vais le faire en 4 parties.
Type hints en python
Cons
Tout d'abord je veux parler de l'utilisation du type hints. J'ai mis beaucoup de temps à y venir parce que je trouve que dans le monde python, le typage est souvent un faux problème. Python adopte une philosophie de duck typing : si ça a des pieds palmés, si ça a un bec, c'est un canard.

Magnifique photo d'un canard
Si les opérations que tu veux réaliser sur ton objet nécessite seulement qu'il a les pieds palmés et un bec, alors peu importe que ce soit un canard, un ornithorynque, ou Arielle Dombasle.
Les type hints dans Python, c'est un outil qui se veut, à la base, informatif et documentaire. C'est une indication de ce que la méthode attends et retourne. Ce n'est pas contraignant (même si mypy permet de le rendre contraignant). Mais mon avis jusqu'à présent, c'est que l'utilisation d'une extension pour typer le langage va graduellement amener à faire un pas vers Java, avec des signatures contraignantes, l'esprit du duck typing va s'évaporer, et des API de plus en plus rigides vont voir le jour. Fiables, oui, mais rigides.
On a vu à quel point une trend peut profondément modifier la nature d'un langage avec Typescript. Néanmoins, pour JavaScript, on peut comprendre la création d'un métalangage, dans la mesure où le langage cible est un jouet bourré de défaut. Concernant python, en revanche, j'ai tendance à penser que le même genre de mouvement dans l'écosystème va nous enlever, à terme, les trucs qu'on aime bien dans le langage. Toute cette partie "pythonique" qui fait plaisir, et qui est résumé dans le Zen de Python.
Retour d'expérience
Donc, voilà où j'en étais. J'ai même encore conseillé, dans un audit récent, de laisser en basse priorité la mise en oeuvre du typing à l'échelle d'un projet, en argumentant qu'il était sans doute le moins important des points relevés lors de l'audit.
Mais c'est évidemment à ce moment-là que j'ai commencé quelques nouvelles applications from scratch pour FrancePunkScene.net et quitte à critiquer quelque chose, autant l'utiliser un peu pour se faire un avis.
Et en vrai... OK. C'est quand même bien cool à utiliser. Déjà parce que cela enrichit la docstring (et sphinx gère très bien l'intégration des hints dans sa documentation). Ensuite, parce que c'est un vrai plaisir à utiliser quand on travaille en TDD. Ça complète totalement le tableau de la conception, ça explicite à fond les intentions, ça aide à garder le fil, à concevoir des meilleurs programmes. C'est un vrai plus pour améliorer ses compétences en design d'application.
Je ne crois pas que ça ait rendu mes interfaces plus ou moins fiables, je l'utilise vraiment comme un outil de confort, de documentation et de conception.
Ce qui me fait enchainer sur le second concept que j'ai teasé un peu plus haut.
Architecture hexagonale dans Django
Une fois que j'ai commencé à typer mes nouvelles classes je me suis mis tranquillement et surtout naturellement à produire du code qui s'inspire de l'architecture hexagonale.
Cons
J'ai toujours eu tendance à éviter ce concept pour deux raisons principales :
1\ Parce que Django :
Je code principalement en Django, qui est un framework MVT (Modèle-Vue-Template) complet et dont les recettes sont presque standardisées. La business logic est dans les modèles, les class based view sont top et on peut facilement étendre les vues génériques pour être extrêmement efficace dans son développement.
Le design pattern MVT fait tout à fait le boulot dans le cadre d'une application web.
2\ Pour éviter de la complexité inutile :
L'application stricto-sensu de l'architecture hexagonale demande d'ajouter beaucoup de complexité, avec une mécanique d'injection de dépendance, la prise en compte de concepts compliqués qui sont surement nécessaires dans le monde Java, ou même le monde Javascript qui demande de pratiquer la programmation évènementielle, mais qui, pour la majorité me semblent totalement sans intérêt dans le monde Python.
Il suffit de lire les livres de l'oncle Bob : ils vulgarisent très mal les concepts qu'ils essaient d'expliquer, et même quelque chose d'aussi simple que l'inversion de dépendances provoque un mal de tête inutile pour être compris, avec une prolifération de diagrammes pas forcément clairs.
Les arguments qui reviennent pour justifier ce coût en complexité sont souvent lunaires, le plus régulier concernant l'ORM : "imagine, tu changes ton moteur de stockage pour passer d'une base de données relationnelles à un stockage objet dans le cul d'une baleine ? Comment tu fais avec ton ORM hein ?"
Indice : ça n'arrivera pas. On peut éventuellement penser à changer de système de gestion de base de données, on peut même imaginer passer d'une base relationnelle à une base non relationnelle, mais les ORM sont justement conçus pour gérer ça (bon, normalement ils sont fait pour des bases relationnelles, pas pour du NOSQL).
Le fait que ce soit stocké dans un SGBD, c'est, normalement, parce que le métier exprime le besoin d'avoir des objets qui aient des relations entre eux, et que tout l'applicatif tourne autour de ces relations.
Le pragmatisme doit l'emporter. Ça induit une contrainte forte entre l'ORM et la logique métier ? Et alors ? Quelles sont les chances d'avoir besoin d'utiliser ce code en dehors de ce contexte ?
- Faibles ? Restons pragmatique, et n'ajoutons pas de couche d'abstraction inutile.
- Moyennes ? Commençons à penser au coût de migration. Passer de L'ORM Django à SQLAlchemy n'est pas forcément mission impossible, surtout avec les IA génératives et une bonne couverture de tests. Cette migration, si elle arrivait, n'aurait lieu qu'une fois. Est-ce que ça vaut le coup ?
- Fortes ? Tu soupçonnes que ta méthode qui calcule la somme totale d'une facture en prenant en compte les bons taux de TVA pour chaque ligne puisse être utilisée un jour sur des objets qui ne sont pas forcément issus de ta base de données ? Alors là oui, effectivement, ça va valoir le coup de sortir cette logique de là.
En bref, c'est un arbitrage à faire en début de projet, et il va vraiment dépendre du projet.
BONUS\ Parce que les adeptes de l'architecture hexagonale sont pédants comme aucuns autres développeurs
Attention
Dans ce paragraphe, l'auteur laisse son objectivité de côté; Toute ressemblance avec une critique objective serait purement fortuite.
Merci de votre compréhension
Il suffit de voir comment ils appellent ça entre eux : la clean-archi. Ces gens-là sont persuadés que leur choix d'archi est le meilleur, le standard, l'architecture ultime du développement. Ils sont persuadés que tout programme qui ne suit pas ces concepts sont de la dette technique qu'il faut remplacer.
Je trouve que c'est de la fainéantise. Vouloir appliquer de l'architecture hexagonale partout est peut-être, pour certaines personnes, une manière de ne pas chercher à comprendre la logique du framework (dans son sens le plus large) dans lequel on travaille. Je l'ai fait sur du WordPress, il y a peu de temps, par exemple. Je n'avais pas envie de faire du code qui rentre dans le moule Wordpress, parce que je n'aime pas ce CMS. Alors, j'ai fait ma petite application agnostique de son côté, je l'ai branché à WP, ça marche, tout le monde est content.
Mais ce n'est pas clean d'introduire différents concepts dans la même application. Vouloir créer sont petit services indépendants dans un système "complexe" est une fuite en avant, qui nous empêche de comprendre le système dans sa globalité, via l'argument "je n'ai pas besoin d'en savoir plus". Ca va potentiellement mener à de la redondance et à de la perte d'efficacité, sinon de performance.
On a été ces gens-là, quand on est arrivé avec nos frameworks MVC modernes au milieu des années 2000. On a très bien appris, depuis, que non, nos concepts, nos langages, nos frameworks, ne sont pas les seuls à exister, ne sont pas la quintessence de la programmation. Les adeptes de la clean archi y viendront aussi.
BREF
Retour d'expérience
Voilà où j'en étais quand, en pleine séance de TDD et en utilisant les type hints, je me suis dit que, quand même, y a des choses vraiment pratiques dans les concepts de l'architecture hexagonale. De manière pleinement pragmatique, il y a quand même un niveau d'approche qui permet de rester proche des concepts Django tout en s'inspirant de cette fameuse clean archi. Par exemple, ça fait déjà un petit temps que je travaille avec le concept des use cases quand j'ai des tâches asynchrones à réaliser. Mes tasks celery sont des petites fonctions qui invoquent des uses cases, qui pourraient être invoqués dans d'autres contextes. C'est donc naturellement que j'ai commencé à en écrire dans des contextes de transactions http classiques.
Très sommairement, mon architecture ressemble donc à ça.
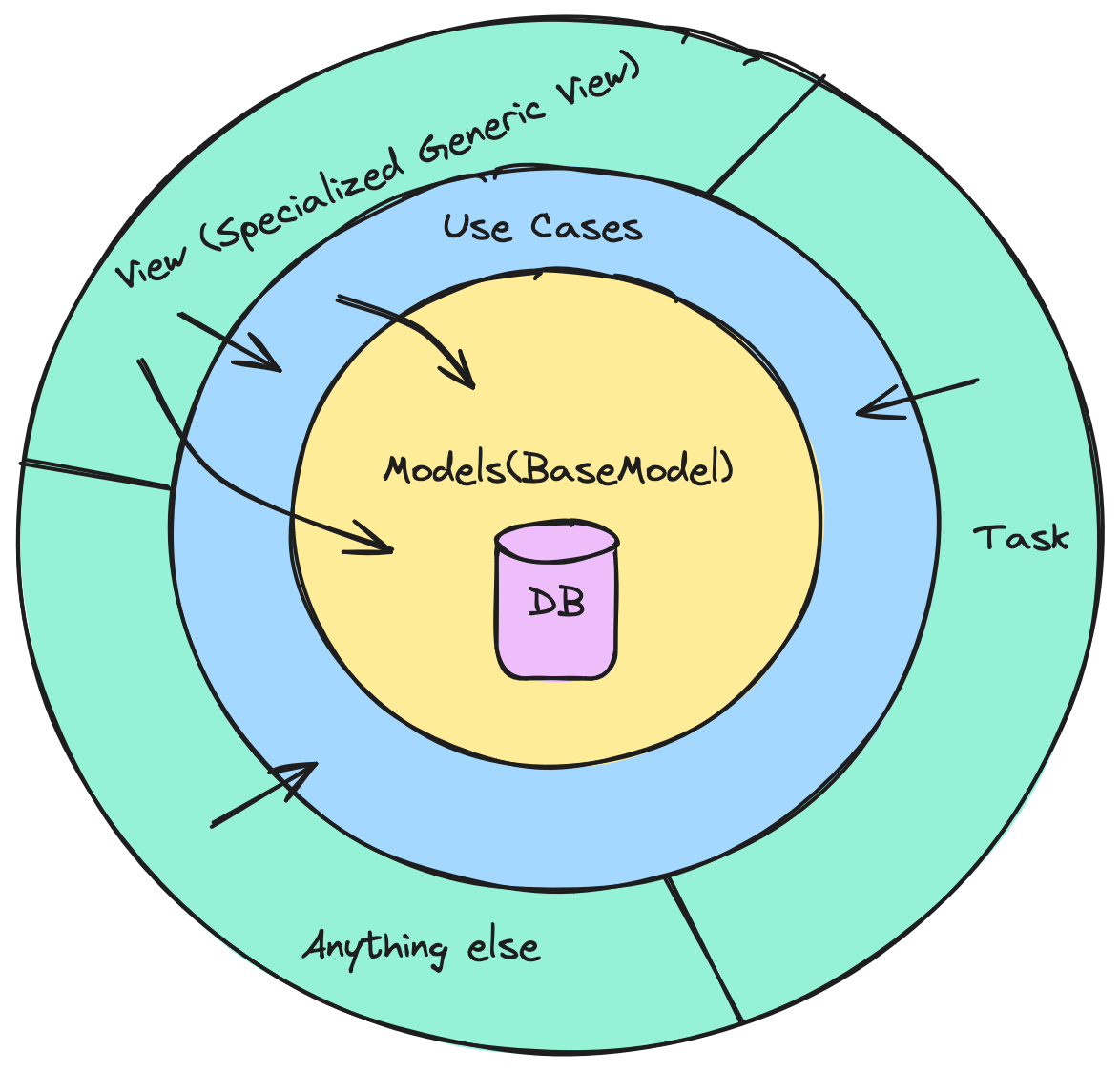
Les vues continuent la plupart du temps de manipuler les modèles, comme c'est courant en Django, mais je commence à passer de plus en plus souvent par cette couche intermédiaire.
De plus, je commence aussi à faire évoluer mon mindset en créant des entités pour tous les items qui ne sont pas des items stockés directement en base de données. Et alors là, j'y vais à la fois avec du typing, mais jusqu'au bout, puisque je vais jusqu'à utiliser pydantic.
Exemple
Prenons un exemple concret : un menu. Imaginons qu'on veuille ajouter dans une vue Django un menu sur un ensemble de pages (une interface de gestion par exemple). Ce menu dépend du niveau de droits de l'utilisateur.
La façon de faire dans l'esprit Django consiste à créer une Mixin qui ajoute, via la méthode get_context_data, un objet menu dans le contexte.
Imaginons une version simplifiée :
class MenuMixin:
ordered_items = [
{'title': 'entry_a', 'url': reverse('app:url_name'), 'perm': 'has_right_to_app_a'},
{'title': 'entry_b', 'url': reverse('app:other_url_name'), 'perm': 'has_right_to_app_b'},
{'title': 'entry_c', 'url': reverse('app:yet_another_url_name'), 'perm': 'has_right_to_app_c'},
]
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
user_menu = []
for item in self.ordered_items:
if self.request.user.has_perm(item.get('perm')):
user_menu.append(item)
context['menu'] = user_menu
return context
C'est dry, c'est simple, ça fonctionne. Mais il faut bien admettre qu'en terme de testabilité, c'est un peu compliqué. En gros, on aura envie de tester une vue concrète, et de vérifier si, dans son contexte, le menu est correctement injecté. Tester les edge cases va être un peu laborieux et peu performant (puisque ça va nécessiter la génération de toute une vue à chaque fois).
Alors qu'on peut rajouter un peu de complexité, en créant des petites classes pour définir les entités Menu et MenuItem, et en créant un use case assez simple qui va gérer toute cette business logic.
# entities.py
class MenuItem(BaseModel):
name: str
url: str = Field(..., pattern='https?://.*', description='URL of the menu item')
class Menu(BaseModel):
name: str
children: list[MenuItem]
# use_cases.py
from .entities import Menu, MenuItem
from .data import ALL_MENU_ITEMS
def get_menu_for_user(user: User) -> Menu:
menu = Menu(name='main', children=[])
for item in ALL_MENU_ITEMS:
if user.has_perm(item['perm']):
menu.children.append(MenuItem(name=item['title'], url=item['url']))
return menu
Et en faisant comme ça, j'y vois plusieurs avantages :
- La testabilité : on peut facilement commencer par écrire les tests qui vont permettre de designer l'API publique de notre menu. On peut très facilement mocker notre objet User. Avec l'utilisation de
coverageen fin de course, on saura ajouter les quelques cas de tests manquants (souvent les cas limites). - Le design d'application : Ça va nous aider à concevoir une solution élégante
- L'assistance par IA : les noms et signatures des méthodes permettent super facilement à l'IA de proposer une solution qui correspond à ce qu'on attend. On n'y pense pas, mais
Copilotva être vraiment guidé via la signature de la méthode, en particulier les types.
On va donc pouvoir tester notre solution (en admettant qu'on n'ait pas commencé par le test, mais c'est une autre histoire).
# test.py
class UserMock(BaseModel):
perms: list[str]
def has_perm(self, perm):
return perm in self.perms
def test_get_menu_for_user():
# Arrange
user = UserMock(perms=['has_right_to_app_a', 'has_right_to_app_b'])
# Act
result = get_menu_for_user(user)
# Assert
assert len(result.children) == 2
assert result.children[0].name == 'entry_a'
assert result.children[1].name == 'entry_b'Et utiliser la même interface dans notre Mixin de tout à l'heure :
# view.py
class MenuMixin:
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['menu'] = get_menu_for_user(self.request.user)
return contextConclusion
Je pense que ces derniers mois m'ont fait reconsidérer ma façon de concevoir une application Django. Je vais certainement aller plus loin et suivre les quelques principes suivants :
- Plus de logique dans les vues, tout faire passer dans des use_cases. Même la logique pour récupérer le queryset attendu doit pouvoir être extraite. Les vues n'auront qu'un rôle d'orchestrateur entre la requête et la logique métier.
- Utilisation systématique d'entités pour les objets qui ne sont pas issus de la base de données
- Utiliser les annotations de type systématiquement, sauf pour les champs des modèles Django (encore que je me sente prêt à reconsidérer ce dernier point)
En revanche, ce que je ne vais pas faire est inclus dans la liste suivante :
- Utiliser une couche d'abstraction entre le modèle et le use case. Les modèles peuvent être considérés comme des entités à part entière, au prix d'un fort couplage avec le SGBD. Couplage que je tolère sans mal.
- Sortir la business logic des modèles. Je continue de penser qu'une grande partie de la business logic est étroitement lié au modèle
Je me pose encore quelques questions concernant une utilisation de mypy, ou encore de ce que je devrais faire avec les filtres de gabarits (que j'évite d'utiliser au maximum).
Pour mettre à niveau ma base code, je suivrai la règle du boy scout.
En contrepartie, je m'engage à être moins dur avec les gourous développeurs passionnés de l'architecture hexagonale.
Ha, et un dernier conseil pour la route : maintenez votre couverture de code à 100%. Testez chaque ligne de votre application, idéalement chaque branche, et ce, dès le début. Prendre du retard est un enfer à rattraper, et tout ce qui n'est pas testé doit être considéré comme présentant une anomalie. Particulièrement après une mise à jour de librairie. J'en ai fais les frais récemment.
2022 - tominardi.fr